传送口
没有看上一篇文章的可以点击→传送门前往上一篇文章
本次工作
- 将程序进行封装
- 将数据存储在数据库中
- 可以自动翻页进行爬取
开始工作
通过之前的爬取之后我们发现那样写不是怎么好,那么我们就将它封装一下。
通过分析我大致将它分成下面的样子:
import requests
import lxml.html
class Tieba(object):
def __init__(self):
"""
初始化的方法
"""
pass
def make_url_list(self):
"""
就是生成要爬取的url
:return: 让其返回一个列表
"""
pass
def save_url(self, dic_data):
"""
保存数据
:param dic_data: 保存传来的字典数据
:return: 无
"""
pass
def download_url(self, url_str):
"""
要获取页面的内容
:param url_str: 页面地址
:return: 获取页面的结构
"""
pass
def run(self):
"""
主业务逻辑
:return:
"""
pass
分好了之后我们将之前的那个程序拆分一下写到这里对应的方法里面
首先我,我们先将初始化的方法写一下:
def __init__(self, name, pages):
"""
初始化的方法
"""
self.tieba_name = name # 要爬取贴吧的名字
self.pages_download = pages # 要爬取多少页
self.base_url = "https://tieba.baidu.com/f?kw={}&ie=utf-8&pn={}"
self.headers = {"User-Agent" : "Python"}
关于self.base_url,我们去看一下贴吧的翻页问题: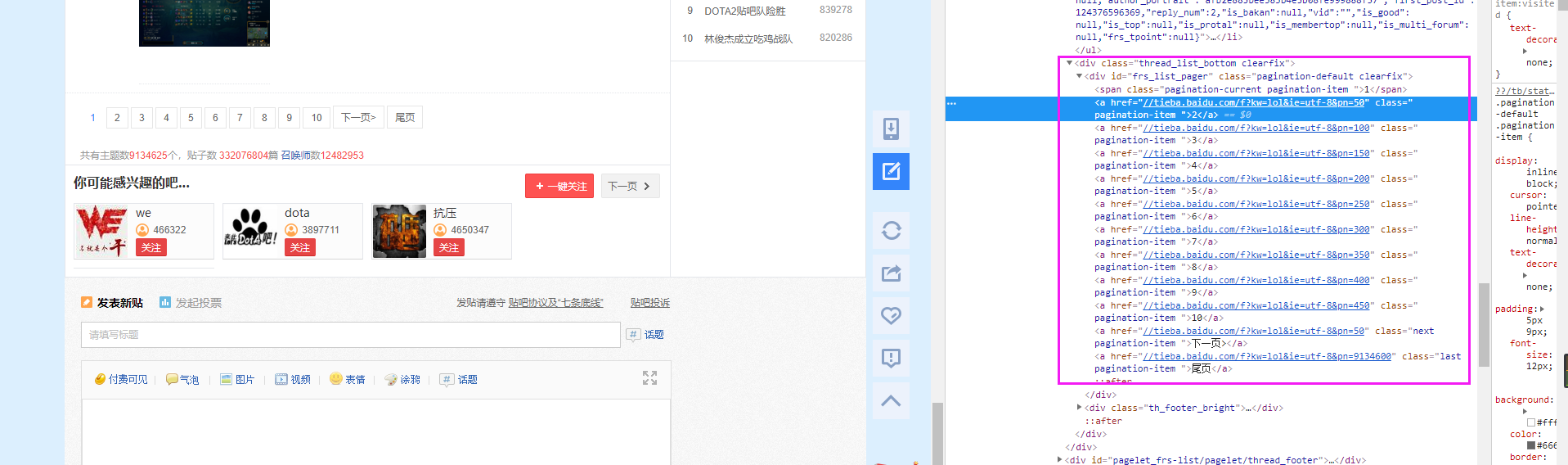
翻页的链接
我们可以看到页面的最后每次增加50的,所以我们可以将make_url_list方法这样写:
def make_url_list(self):
"""
就是生成要爬取的url
:return: 让其返回一个列表
"""
url_lists = []
for i in range(self.pages_download):
download_url = self.base_url.format(self.tieba_name, i * 50)
url_lists.append(download_url)
return url_lists
我们的download_url,也就是做获取页面的那个操作:
def download_url(self, url_str):
"""
要获取页面的内容
:param url_str: 页面地址
:return: 获取页面的结构
"""
response = requests.get(url_str, headers=self.headers)
return response.text
接下来我们可以写一下save_url方法,因为这个就是一个将数据存入数据库的方法,我们可以直接写一下:
def save_url(self, dic_data):
"""
保存数据
:param dic_data: 保存传来的字典数据
:return: 无
"""
db = self.client.test # 选取一个数据库
collection = db.tieba #然后选取一个数据表
collection.insert_one(dic_data) #将数据保存
为了我们后面的增量爬取,我们在写一个方法:checksum:
def checksum(self, content):
"""
对帖子的内容进行加密,后面可以进行增量爬取
:param content: 帖子的内容
:return:
"""
md5 = hashlib.md5()
md5.update(content.encode("utf-8"))
return md5.hexdigest()
将帖子的内容进行加密之后,我们后期可以通过这个进行比对这个帖子是否被重新编辑过
接下来就是我们的主逻辑方法啦~
def run(self):
"""
主业务逻辑
:return:
"""
url_list = self.make_url_list()
for url in url_list:
print("正在爬取",url)
result_text = self.download_url(url)
res = lxml.html.fromstring(result_text)
result_elements = res.xpath("//ul[@id='thread_list']//li[@class=' j_thread_list clearfix']")
for result_element in result_elements:
res_msg = result_element.cssselect("div.threadlist_title > a.j_th_tit")[0]
link = res_msg.xpath(".//@href")[0]
title = res_msg.text
res_author = result_element.cssselect("div.threadlist_author > span.tb_icon_author")[0]
author = res_author.xpath(".//@title")[0].replace("主题作者: ", "")
content_response = self.download_url('https://tieba.baidu.com'+link)
res_content = lxml.html.fromstring(content_response)
con_res_ele = res_content.cssselect("div.d_post_content")[0]
time_res = res_content.xpath("//div[@class='post-tail-wrap']//span[@class='tail-info']")[-1]
content = con_res_ele.xpath(".//text()")[0]
time = time_res.text
data = {
"title": title,
"link": 'https://tieba.baidu.com'+link,
"author": author,
"content": content,
"time": time,
"checksum": self.checksum(content)
}
self.save_url(data)
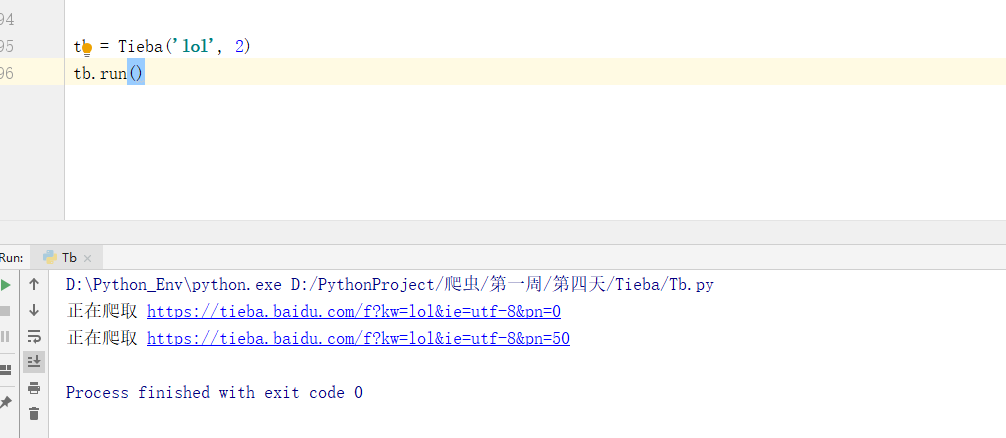
爬取完成

数据库数据
我们可以看到数据已经存进去了,两页数据为什么这么少?看左下角,他是分页显示了输入‘it’就可以查看下面的内容啦
未完待续..