爬取对象
爬取需求
- 爬取用户的发表文章的标题
- 爬取用户的名称
- 爬取用户的发表内容
- 爬取帖子的发表时间
- 将爬取的内容存放到Mongodb中
- 实现自动翻页爬取
- 最好改成增量爬取
工具以及使用到的库
- PyCharm
- requests
- lxml
- pymongo
- queue
爬前小分析
首先我们进入到lol贴吧,然后查看页面,看一下我们需要爬取的内容,紫色区域内是我们需要爬取的内容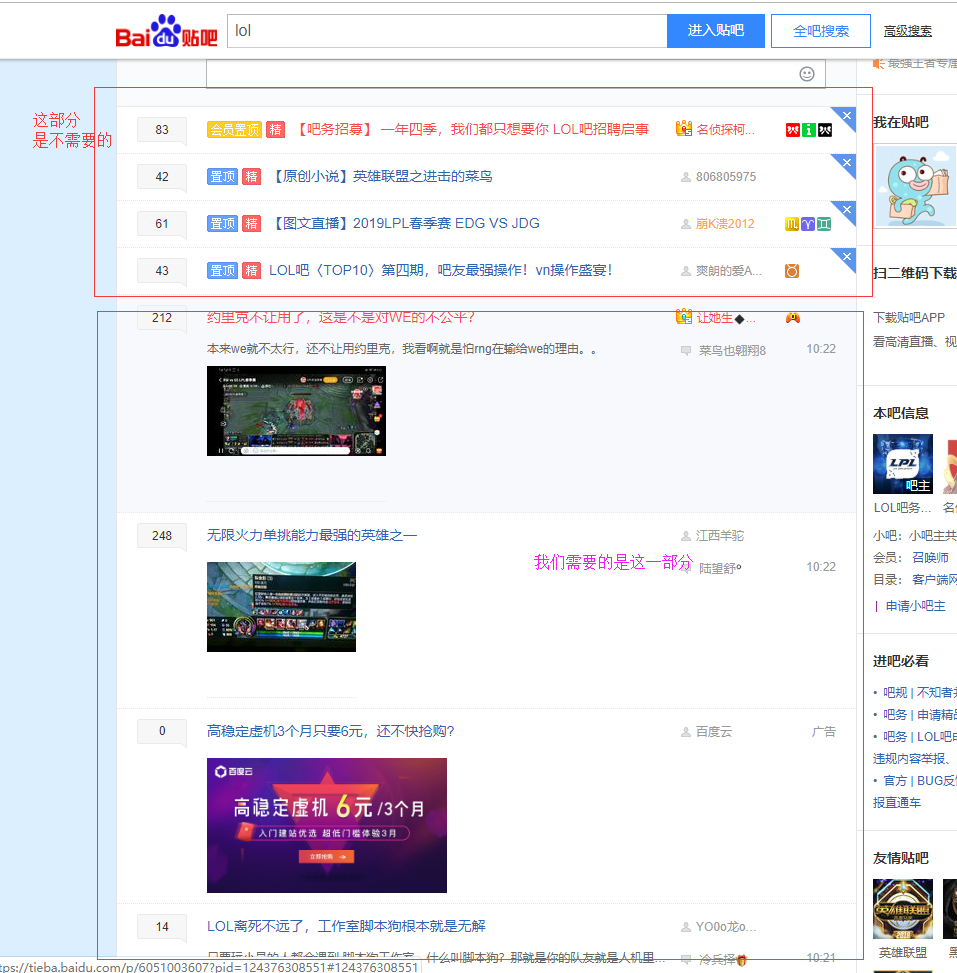
lol贴吧的首页
然后我们去检查[F12]一下,可以发现我们需要的信息在一个ul的标签里面放着,然后查看里面的li标签可以发现,第一个li标签存放的是置顶的帖子,这个不是我们的菜,略过。往下看,发现下面是清一色的li标签[class属性一样的,忽略那些推送广告的标签],这就是我们所需要的东西,然后点击其中一个文章的标题就会看到我们需要的信息[见下图]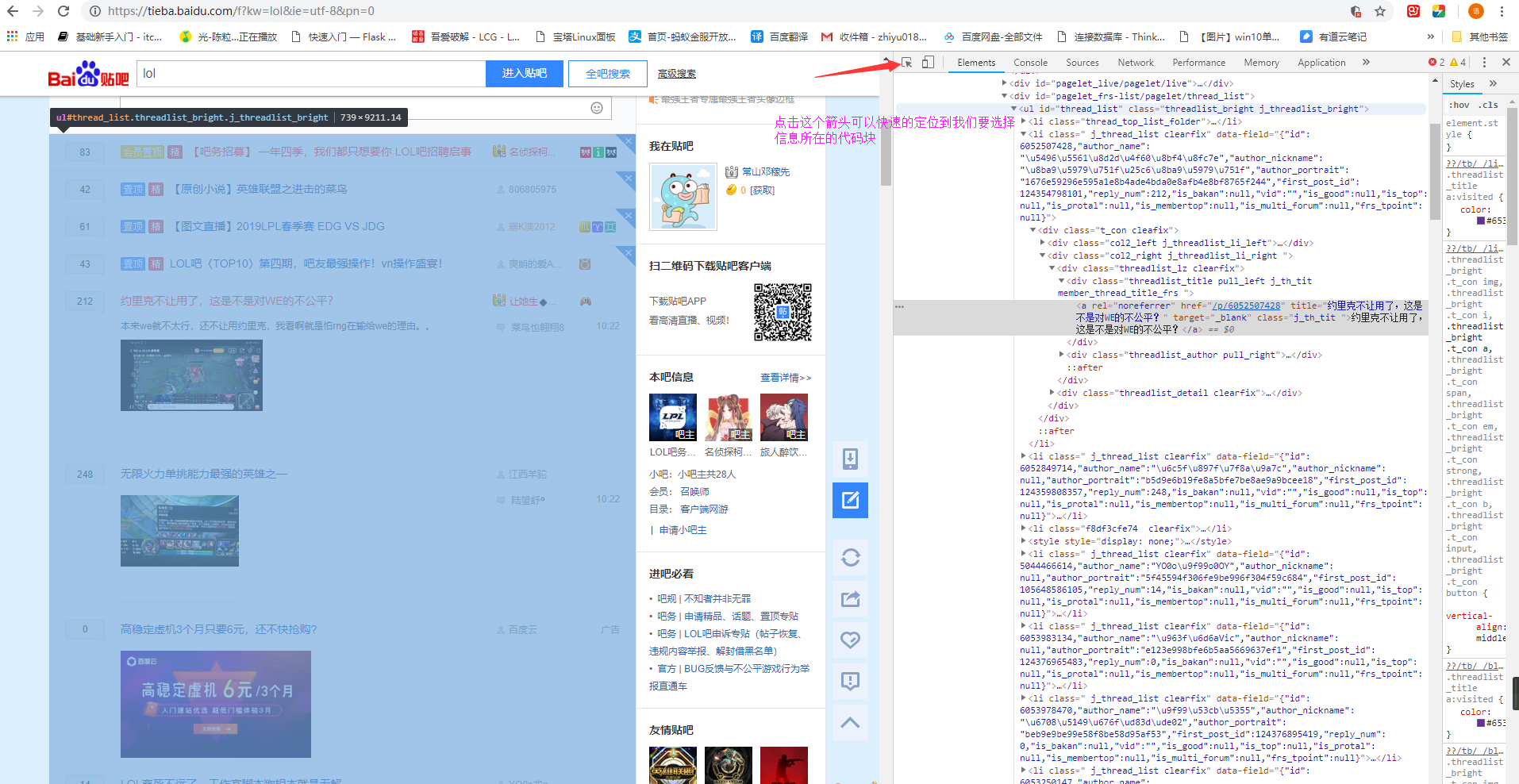
查看代码块 及分析所需要的信息
PS:关于帖子内容的爬取 爬取到的时候再进行分析查看
开始工作
首先我们需要通过requests将网页抓取下来,然后使用lxml对这个页面进行数据的提取:
response = requests.get("https://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=0")
res = lxml.html.fromstring(response.text)
result_elements = res.xpath("//ul[@id='thread_list']//li[@class=' j_thread_list clearfix']")
此处个人看法,我们不要直接去拿文章的标题和作者,前面分析看到我们要获取的所有的信息都在
ul标签里面,而且都是统一存放在样式一样的li内,我们应该先获取到所有的li这个节点的内容,去进行遍历这样会好很多

result_elements打打印结果
他是一个列表,那么我们就通过循环来获取一下我们需要的内容吧。我们通过检查[F12]发现我们要获取的帖子的标题在一个div包裹的a标签中,其中div的class的值有好几个,那么我们就使用cssselect来获取他的内容比较好,不然通过xpath来获取的话可能要写很长很长,其中帖子的链接也存在于这里面的a标签处这样的话我们可以一块获取了,我们再看一下作者名字所在的位置: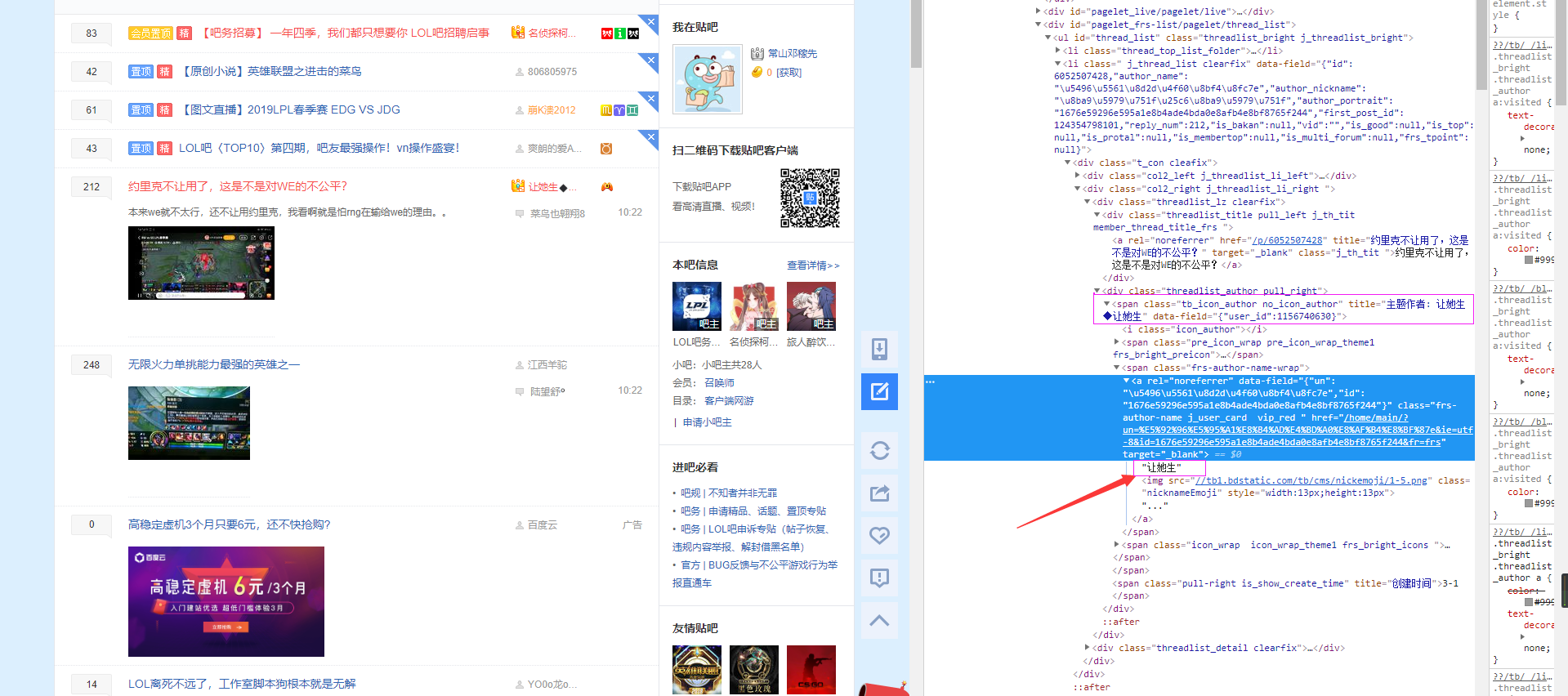
作者的名字
我们可以看到,我们所定位到的地方作者名字是没有显示全的,但是可以看到在上面的那个span标签里面是显示了的,那么作者的标签我们就从上面的那个span标签来获取,如果你要说我们获取的是作者的名字,上面还显示主题作者四个字的话,我们可以使用replace将让去掉,代码如下:
for result_element in result_elements:
res = result_element.cssselect("div.threadlist_title > a.j_th_tit ")[0]
link = res.xpath(".//@href")[0]
title = res.text
res_author = result_element.cssselect("div.threadlist_author > span.tb_icon_author")[0]
author = res_author.xpath(".//@title")[0].replace("主题作者: ","")
print(BASE_URL+link)
print(title)
print(author)
print('*' * 20)
其中
BASE_URL是我们要拼接帖子地址用到的BASE_URL = "https://tieba.baidu.com"
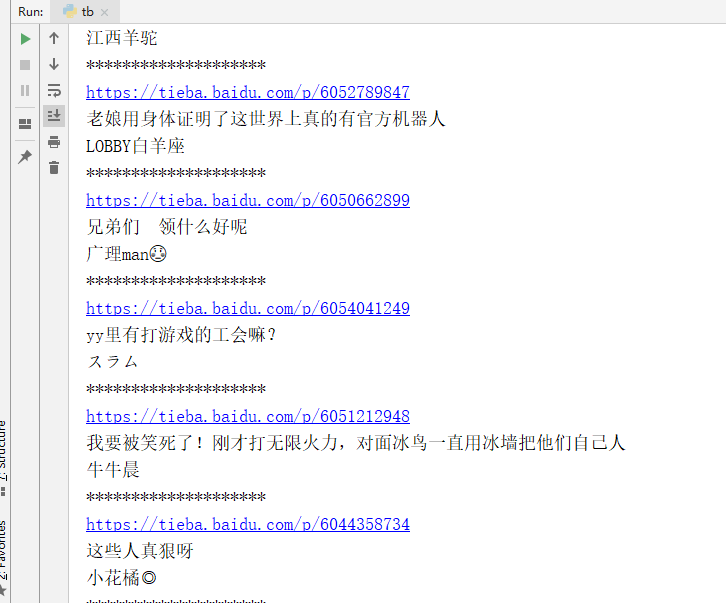
运行结果
下面我们就来获取文章内容以及时间,随便打开一篇帖子,然后我们按照上面的方法检查[F12]一下,我们可以看到:
帖子的部分
其实有的帖子是带有图片的,还有的是带有视频的,我们暂时不获取那些东西,我们来暂时只获取一下帖子的文字,我们看到文章部分是在一个div标签里面,其中class的值有两个,那么我们就使用cssselect来对文字进行获取:
content_response = requests.get(BASE_URL+link)
res_content = lxml.html.fromstring(content_response.text)
con_res_ele = res_content.cssselect("div.d_post_content")[0]
content = con_res_ele.xpath(".//text()")[0]
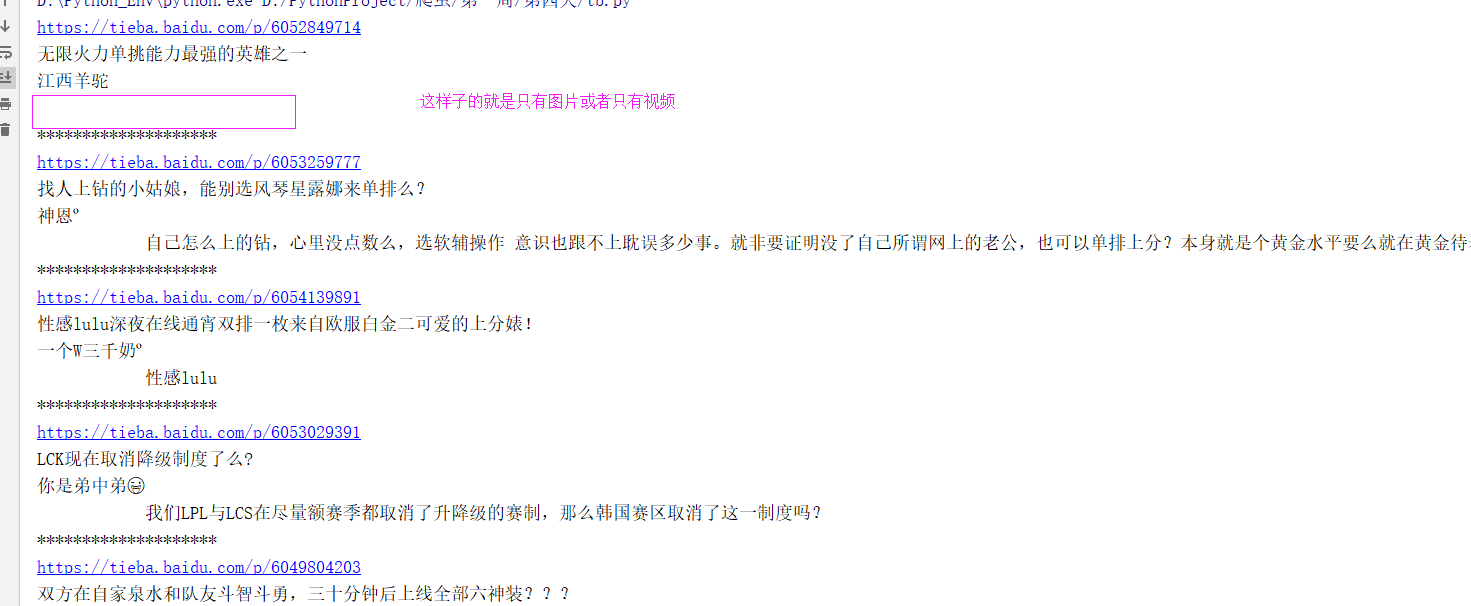
文章获取成功 空白的就是单单只有图片或者只有视频
时间呢,我们可以看到是在div包裹的span标签内部,我们可以看到这两个span标签class的值是一样的,但是不管是div还是span他们的class值都是一个,那么我们就使用xpath来获取他们:
time_res = res_content.xpath("//div[@class='post-tail-wrap']//span[@class='tail-info']")[-1]
time = time_res.text
这里有可能会有人说也可以使用[1]来获取呀,看下图
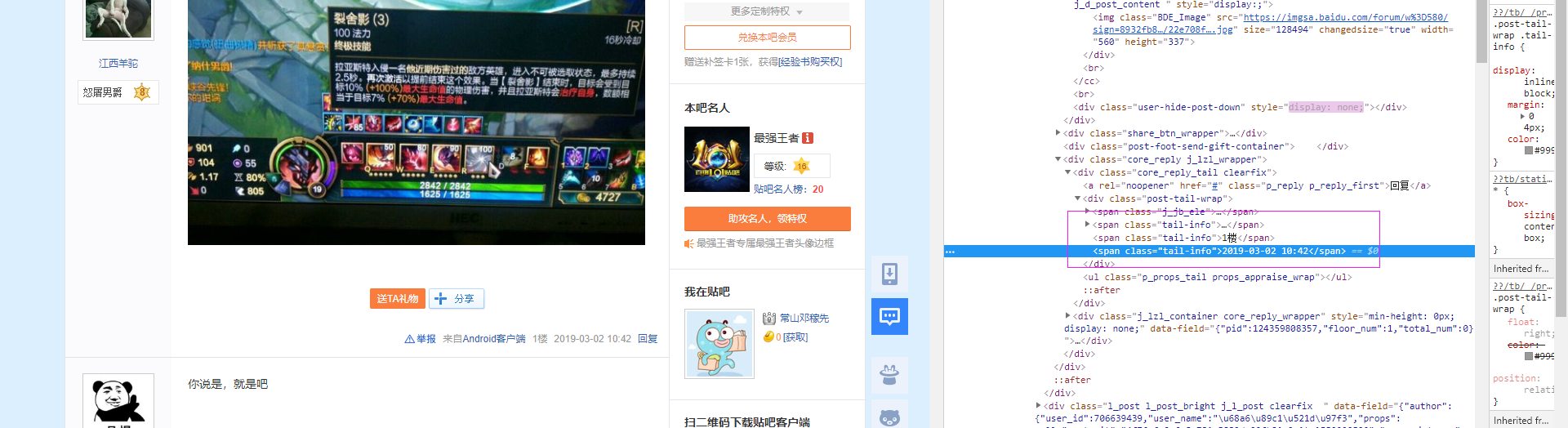
关于时间获取
我们可以看到这里面的class一样的span有三个,而包含时间的始终都在最后一个,所以我们使用[-1]来获取更好一点,那么我们的最终的代码打印一下结果看一看:
import requests
import lxml.html
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36"
}
BASE_URL = "https://tieba.baidu.com" # 为了拼接帖子的链接
response = requests.get("https://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=0")
res = lxml.html.fromstring(response.text)
result_elements = res.xpath("//ul[@id='thread_list']//li[@class=' j_thread_list clearfix']")
for result_element in result_elements:
res = result_element.cssselect("div.threadlist_title > a.j_th_tit ")[0]
link = res.xpath(".//@href")[0]
title = res.text
res_author = result_element.cssselect("div.threadlist_author > span.tb_icon_author")[0]
author = res_author.xpath(".//@title")[0].replace("主题作者: ","")
content_response = requests.get(BASE_URL+link)
res_content = lxml.html.fromstring(content_response.text)
con_res_ele = res_content.cssselect("div.d_post_content")[0]
time_res = res_content.xpath("//div[@class='post-tail-wrap']//span[@class='tail-info']")[-1]
content = con_res_ele.xpath(".//text()")[0]
time = time_res.text
print(BASE_URL+link)
print("标题:",title)
print("作者:",author)
print("内容:",content)
print("时间:",time)
print('*' * 20)

结果显示
其他的
完了么?其实还没有,我们只是简单的讲这个程序写了出来,我们还需要将它封装一下,还有最重要的一点就是我们还没有完成使用MongoDb进行存储以及增量的爬取其余的见下一篇文章